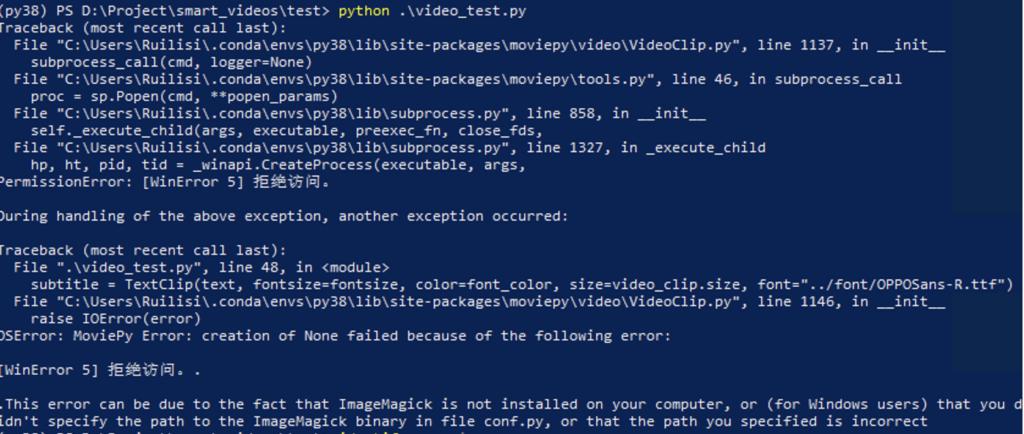
在早期我们还需要不断地拼凑最大limits来获取交易数据
但是币安已经提供了下载链接,理论上我们只需要清洗一下数据就ok了,现在获取数据已经不用那么麻烦了,一分钟获取了一年的,效率还是很高的

import os
import zipfile
import pandas as pd
import requests
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
def get_binance_kline(symbol, time_interval, date, file_path):
"""
获取k线数据
:param symbol:
:param time_interval: 1s, 1m, 5m, 15m, 30m, 1h, 2h, 4h, 6h, 8h, 12h, 1d
:param date: xxxx-xx 2021-01
:param file_path:
:return:
"""
url = f"https://data.binance.vision/data/spot/monthly/klines/{symbol.upper()}/{time_interval}/{symbol.upper()}-{time_interval}-{date}.zip"
response = requests.get(url)
# 检查文件夹是否存在
if not os.path.exists(file_path):
os.makedirs(file_path)
with open(f"{file_path}/{symbol.upper()}-{time_interval}-{date}.zip", "wb") as f:
f.write(response.content)
def unzip_file(zip_src, dst_dir):
"""
解压缩文件
:param zip_src: 压缩文件路径
:param dst_dir: 解压缩路径
:return:
"""
r = zipfile.is_zipfile(zip_src)
if r:
fz = zipfile.ZipFile(zip_src, 'r')
for file in fz.namelist():
fz.extract(file, dst_dir)
else:
print('This is not zip')
# 处理数据
def clear_data(timestamp):
for file in os.listdir(f"{BASE_DIR}/data/binance/{timestamp}"):
if file.endswith(".zip"):
unzip_file(f"{BASE_DIR}/data/binance/{timestamp}/{file}", f"{BASE_DIR}/data/binance/{timestamp}")
os.remove(f"{BASE_DIR}/data/binance/{timestamp}/{file}")
# 合并csv
for file in os.listdir(f"{BASE_DIR}/data/binance/{timestamp}"):
if file.endswith(".csv"):
os.system(f"cat {BASE_DIR}/data/binance/{timestamp}/{file} >> {BASE_DIR}/data/binance/{timestamp}/all.csv")
os.remove(f"{BASE_DIR}/data/binance/{timestamp}/{file}")
df = pd.read_csv(f"{BASE_DIR}/data/binance/{timestamp}/all.csv", names=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11],
header=None)
if df.empty:
pass
df.rename(columns={0: 'MTS', 1: 'open', 2: 'high', 3: 'low',
4: 'close', 5: 'volume'}, inplace=True)
df['candle_begin_time'] = pd.to_datetime(df['MTS'], unit='ms')
df = df[['candle_begin_time', 'open', 'high', 'low', 'close', 'volume']].copy()
# 去重、排序
df.drop_duplicates(subset=['candle_begin_time'], keep='last', inplace=True)
df.sort_values('candle_begin_time', inplace=True)
df.reset_index(drop=True, inplace=True)
df.to_csv(f"{BASE_DIR}/data/binance/{timestamp}/all.csv", index=False)
file_path = f"{BASE_DIR}/data/binance/{timestamp}/all.csv"
return file_path
if __name__ == '__main__':
symbol = "BTCUSDT"
time_interval = "5m"
start_time = "2021-01"
end_time = "2022-02"
# 获取当前时间戳做为文件夹名
current_timestamp = int(time.time())
# 遍历月份
start_year = int(start_time.split("-")[0])
start_month = int(start_time.split("-")[1])
end_year = int(end_time.split("-")[0])
end_month = int(end_time.split("-")[1])
for year in range(start_year, end_year + 1):
for month in range(1, 13):
if year == start_year and month < start_month:
continue
if year == end_year and month > end_month:
continue
date = f"{year}-{month:02d}"
logger.info(f"symbol:{symbol},date: {date}")
get_binance_kline(symbol, time_interval, date, f"{BASE_DIR}/data/binance/{current_timestamp}")
# 清洗数据
file_path = clear_data(current_timestamp)
return flie_path