LLaMA-Factory介绍
LLaMA-Factory是一个基于Gradio的可视化界面,可以导入模型训练以及训练模型,对新手十分友好,且可以可视化训练过程。
项目部署
首先git clone LLaMA-Factory仓库
git clone https://github.com/hiyouga/LLaMA-Factory.git
使用conda创建所需要环境
conda create -n llamaFactory python=3.10
# 安装所需依赖
pip install -r requirements.txt
项目启动
由于我使用的wsl2可能和部分读者不一样,推荐使用linux ubuntu
# 启动LLaMA board
python src/train_web.py
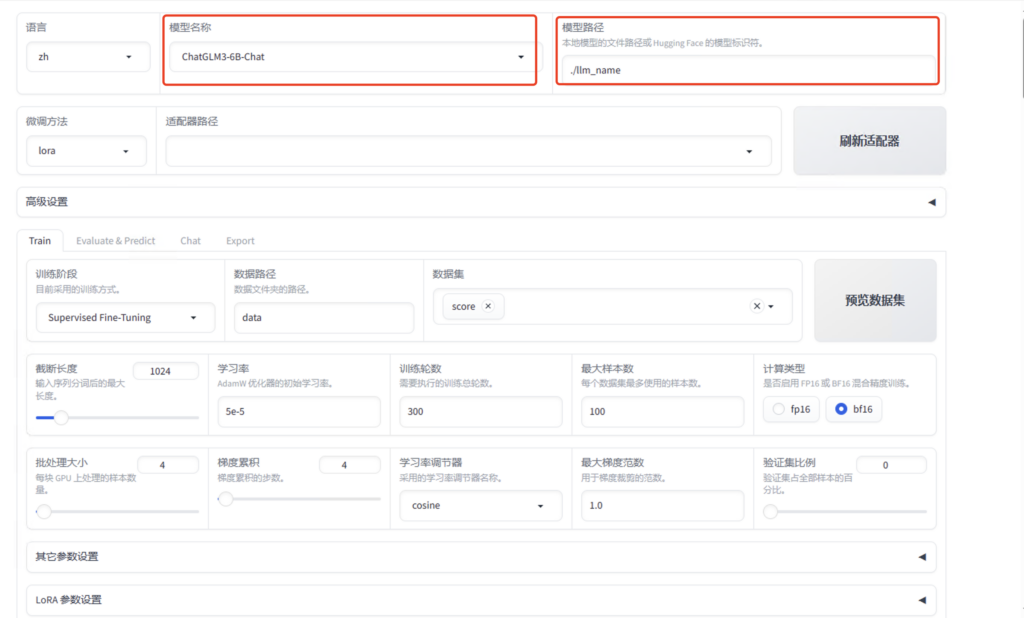
以上就是启动页面,注意红框部分
- 选择模型名称
- 选择完模型之后模型路径会默认为Hugging Face模型标识符,我推荐下载到本地
当选择完之后我们就可以直接进行模型的加载

点击chat,选择加载模型,等待模型加载完毕,即可弹出对话框
准备数据集
数据集需要特定的格式
在项目的data文件夹下操作
项目默认的example中存在两个比较重要的文件分别为:dataset_info.json以及examples.json
dataset_info.json
{
"你的数据集名字": {
"file_name": "文件名.json",
"file_sha1": "文件sha1607f94a7f581341e59685aef32f531095232cf23"
},
"alpaca_zh": {
"file_name": "alpaca_data_zh_51k.json",
"file_sha1": "e655af3db557a4197f7b0cf92e1986b08fae6311"
}
}
examples.json
其中instruction,output是必须的,其他的可选
[
{
"instruction": "听起来很不错。人工智能可能在哪些方面面临挑战呢?",
"input": "",
"output": "人工智能面临的挑战包括数据隐私、安全和道德方面的问题,以及影响就业机会的自动化等问题。",
"history": [
["你好,你能帮我解答一个问题吗?", "当然,请问有什么问题?"],
["我想了解人工智能的未来发展方向,你有什么想法吗?", "人工智能在未来的发展方向可能包括更强大的机器学习算法,更先进的自然语言处理技术,以及更加智能的机器人。"]
]
},
{
"instruction": "好的,谢谢你!",
"input": "",
"output": "不客气,有其他需要帮忙的地方可以继续问我。",
"history": [
["你好,能告诉我今天天气怎么样吗?", "当然可以,请问您所在的城市是哪里?"],
["我在纽约。", "纽约今天晴间多云,气温最高约26摄氏度,最低约18摄氏度,记得注意保暖喔。"]
]
}
]
获取文件的sha1
sha1sum example.json
开始训练
当我们准备好数据集之后

选择我们的数据集,点击开始训练,便可以可视化看到我们训练的过程了。